重線形回帰やってみた
今回は、携帯電話関連会社であるKDDI、ソフトバンク、楽天の株価でNTTの株価を推定する重線形回帰をやってみた。
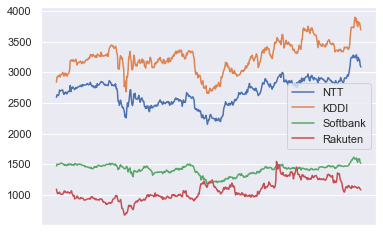
株価の繊維をグラフで表示すると上記の通りになるので、KDDIとNTTとの関係に比べると、あまり意味のない結果になるかなと思ったのですが、意外とそんな結果にはなりませんでした。
ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import seaborn as sns
sns.set()
データの読み込み
data = pd.read_csv('mibile_company_stock_price_2020-10-01_2021-09-30.csv')
data.head()
data.describe()
回帰の作成
従属変数と独立変数の宣言
y = data['NTT']
x1 = data[['KDDI','softbank','rakuten']]
回帰
x = sm.add_constant(x1)
results = sm.OLS(y,x).fit()
results.summary()
表の見方
1番目の表
Adj. R-squared: 自由度修正済み決定係数、重回帰分析のように複数の独立変数がある場合にペナルティが与えられるようにR-squaredが計算される。この値が1に近づけば誤差は小さくなっているので、モデルが改善されていると判断できる。前回の単回帰の時の結果が0.727だったので、結果がよくなっていることになる。
F-statistic: F値、大きい方が良い。単回帰分析のF値は1288だったので、単回帰分析の結果の方が優位であると言えるらしい
Prob (F-statistic): F検定のP値、一般的には0.05以下であれば良い。今回もOK
2番目の表
P>|t|: t検定のP値、前回も説明した通り、一般的には0.05以下であれば意味がある独立変数。ということで、ソフトバンクも楽天もある程度意味があるらしい。
ということで、意外と追加してもパフォーマンスは上がったようです。
ということで、念のため、回帰した結果を用いて、単回帰と重回帰をグラフ表示してみると以下の通り。確かに良くなってそう。
data["single NTT"] = 148.3029 + 0.7811 * data['KDDI']
data["multi NTT"] = -588.0258 + 0.4863 * data['KDDI'] + 1.0179 * data['softbank'] + 0.2364 * data['rakuten']
plt.plot(data["date"],data[["NTT","single NTT","multi NTT"]], label=["NTT","Calculated by KDDI",u"Calculated by KDDI, Softbank, Rakuten"])
#yhat = x1*0.7811+148.3029
#fig = plt.plot(x1,yhat, lw=4, c='orange', label ='regression line')
plt.xlabel('date', fontsize = 20)
plt.legend()
plt.xticks([])
plt.show()

ただ、線形回帰を利用する上での注意点がいくつかあるらしく、そもそも、時系列のデータには使ってはいけないらいい。以下が線形回帰を利用する条件
1, 自己相関がないこと。
時系列データの場合は、週や月など周期性が見られるため、自己相関がないとは言いにくい。
Durbin-Watson: この値は0から4の値を取るが、1以下、または3以上だと自己相関がある可能性が高い
ということで、株価は自己相関があるので、線形回帰は利用できない。実際に上の結果の3番目の表を見るとこの値は0.113になっている。
2, 多重共線性が無いこと。
これは、独立変数間に関連性がないことを意味します。株価の場合は、銘柄間に全く関連性がないことを示すのは難しいですが、銘柄間の相関を調べることによってある程度調べられますね。こちらは、この後で図示してみてます。
3, 線形性が無いこと。
これは独立変数と従属変数の間に線形性がない場合ですね。株価の場合は、ありそうなので、そこは問題ないかと
4, 内成性が無いこと。
独立変数と残差に関係が無いこと。必要な独立変数を除いてしてしまった場合にこれが発生する
結果だけ見るとこの回帰から大幅に外れたら買ってみるとかしてもそんなに悪くなさそうなんだけどなー。
おまけ 独立変数(株価)間の相関
data_corr = data[["KDDI","softbank","rakuten"]].corr()
sns.heatmap(data_corr, vmax=1, vmin=-1, center=0)

data_corr
この通り、ソフトバンクと楽天の間の株価の相関は低いが、それ以外はそれなりに相関がありそう。
Follow me!