単線形回帰をやってみた。
KDDIの株価でNTTの株価を推定する単線形回帰をやってみた。
ライブラリのインポート
In [1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import seaborn as sns
sns.set()
データのインポート
今回は、2020年10月1日から2021年9月30日のモバイル関係銘柄の株価(NTT、KDDI、ソフトバンク、楽天)のインポート
In [2]:
data = pd.read_csv('mibile_company_stock_price_2020-10-01_2021-09-30.csv')
In [3]:
data.head()
Out[3]:
In [4]:
data.describe()
Out[4]:
回帰の作成
従属変数と独立変数の定義
今回の場合は、KDDIの株価からNTTの株価を算出するので、NTTが従属変数、KDDIが独立変数
In [5]:
y = data['NTT']
x1 = data['KDDI']
データの確認
In [6]:
plt.scatter(x1,y)
plt.xlabel('NTT',fontsize=20)
plt.ylabel('KDDI',fontsize=20)
plt.show()
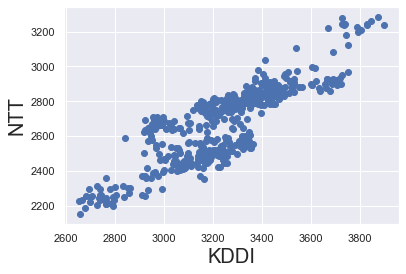
この結果を見る限り、NTTとKDDIの株価はかなり相関が高そう。
回帰の実行
In [7]:
x = sm.add_constant(x1)
results = sm.OLS(y,x).fit()
results.summary()
Out[7]:
1番目の表(回帰の結果)の見方
Dep. Variable:予測する値、今回の場合はNTT
Model: 回帰モデル、OLS(Ordinary Least Square)は最小二乗回帰
Method: 回帰モデルの最適化方法、Least Squaresは残差が最も小さくなるように最適化
R-squared: 決定係数、この結果を見て従属変数と独立変数のマッチ度を確認する。1だと回帰のばらつきについて完全に説明している。0だと何も説明していない。ということで1に近ければ近いほど良い。0.727は悪くない値らしい
2番目の表(変数の結果)の見方
constの行が切片、それ以降の行は独立変数の結果を示している。
coef: constが切片、それ以降の行(今回はKDDIだけ)は傾きを表している
std err: 標準誤差
t: t値
P>|t|: P値、これが重要。一般的には、0.05以上だとその独立変数は意味がないと判断してよいらしいので除外した方が良い。今回の場合は、全て0.05以下なので問題なし。
Follow me!